The faker's guide to reading (x86) assembly language
Assembly code scares people. There’s a good reason for that. For many people, writing code in assembly language seems equivalent to writing code in ancient dwarven runes, or calculating pi in roman numerals. The fact that RollerCoaster Tycoon was almost completely written in assembly language sounds almost too amazing to be true. Many programmers view assembly language as some combination of ancient, arcane, inscrutable, useless, and complex.
Despite all that, I have a secret to share with you. Reading assembly language is not really that hard. Or at the very least, it’s an order of magnitude easier than writing assembly language. There are a few reasons why that’s true, but before we dive into that, let me first tell you why you should care about assembly language.
Why should I care?
For most people that write in languages that compile to native code, assembly language represents the fundamental building blocks for every program that we build and run1. If you’ve ever had to troubleshoot something where you absolutely, 100%, MUST understand what a line of code does… reading the assembly for the code is what you should do. Not reading the C++ source, Rust source, or even C source. And the reason for that is that source code in every language will lie to you. Not necessarily due to any fault in the programming language or compiler, but due to the limits of our own comprehension. Complex or unfamiliar language features, undefined behavior, or simply poorly written code can be difficult to understand to see what’s really going on. But the assembly code will always tell you the truth.
And besides that, there are the typical cases where you read assembly language: when you don’t have the source code. Reverse engineering something to understand how it works shouldn’t be seen as an unapproachable skill. It’s something every programmer should have some level of understanding of, especially if you run code on a closed source operating system or use libraries without source code.
But most importantly, understanding assembly language is essential to understanding how things really work, and can give you better insights into how things work, whether you’re building systems up or tearing systems down. Reading assembly language is not a replacement for proper reverse engineering tools like Ghidra or IDA, but it is a necessary complimentary skill.
Why reading is easier than writing
One of the hardest parts of assembly language are the fact that there are so many different instructions. The 8086 instruction set started with 81 different instructions. On a modern Intel CPU, that number is closer to 1000. You could imagine trying to find the right instruction for a specific situation would be difficult. In reality, the number of instructions you need to learn to read is quite small. In one binary I looked at, 83% of the instructions used were the 10 most frequent instructions, and many of the top 30 instructions are just slight variations (like AND and OR).
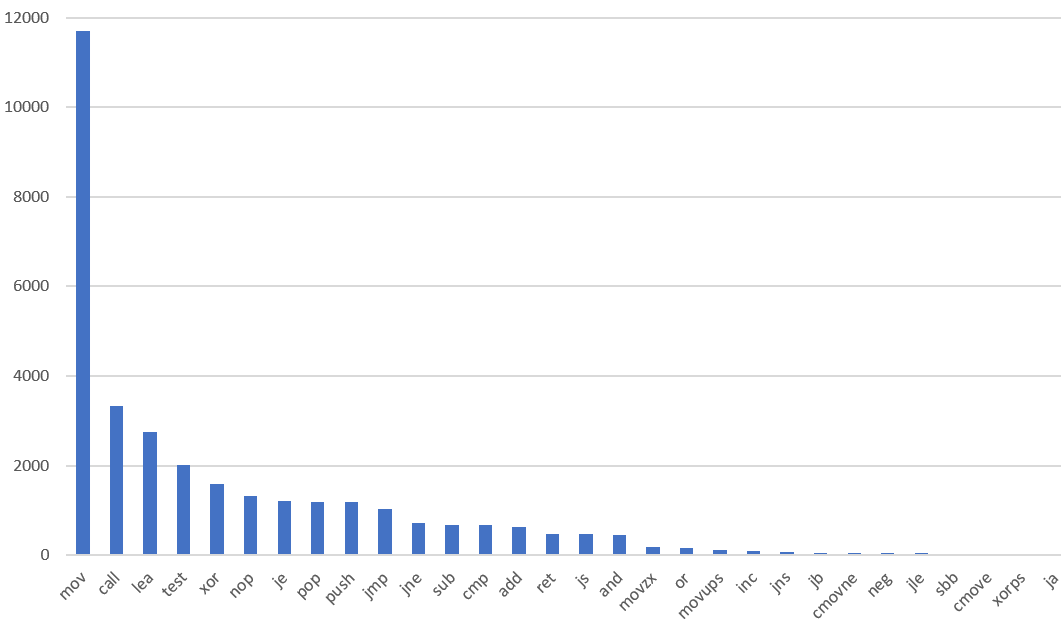
Here’s a chart I made showing the relative frequency of the 30 most common instruction types I saw in one binary. I suspect you would see a similar graph on other architectures, but on x86 you’ll see a particularly long tail due to the large number of instruction types. You can understand a very large chunk of assembly code if you just know the most common instructions.
How to read assembly
Hopefully I’ve convinced you that learning to read assembly language is important and not as hard as you think. So let me give you a little crash course in x86 assembly.
Two flavors: AT&T and Intel syntax
For historical reasons, there are two “flavors” of disassembly syntax for x86. One is called “Intel” and the other is called “AT&T”. If you live in the Windows world, you may never see AT&T syntax, but some open source tools will default to AT&T syntax so it’s good to recognize when you’re dealing with it.
The biggest difference you’ll see between the two flavors is that the order of operands is reversed! Here’s an example of AT&T syntax:
addl $4, %eax
And here’s an example of Intel syntax:
add eax, 4
Besides the order being swapped, constants also get prefixed with $, and registers are prefixed with %. Some mnemonics also have a letter appended to indicate the size of the operands, such as l for 32-bit operands.
Depending on the tools you are using, you may not have a choice of which syntax to use. WinDbg only supports Intel syntax, for instance. Many open source tools will default to AT&T syntax, but will have an option to enable Intel syntax. For objdump, you can use -M intel. For instance:
objdump -d -M intel ./a.out
While I’m sure someone has an argument in favor of the AT&T syntax, I’d suggest avoiding it for one simple reason: The Intel manual (SDM) uses Intel syntax, and is a crucial resource to understand how an instruction works. So to avoid confusion, stick with Intel syntax.
The parts of an instruction: mnemonic, operands, and prefixes
A single assembly language unit is an “instruction”, and it has three parts.
The “mnemonic” is the name of the instruction, like “ADD” or “MOV”, which tells you what the instruction does. Most mnemonics are an abbreviated version of a word, like MOV (move), SUB (subtract), or INC (increment). Other operations have an abbreviated phrase as the mneumoic, such as LEA (Load Effective Address), or SAL (Shift Arithmetic Left). There are complex instructions that operate on “vectors” (also known as SIMD or Single Instruction Multiple Data) which tend to have long and complicated names, but luckily you won’t have to read things like PMADDUBSW very frequently (Multiply signed and unsigned bytes, add horizontal pair of signed words, pack saturated signed-words).
Each instruction can take 0 to 3 operands, although 2 operands is the most common. Operands could be registers, constants, or memory locations, but not every type and combination of operand type is available for every instruction. For instance, there is no version of MOV that takes two memory locations, but MOV reg, mem and MOV mem, reg are both available for moving data around.2
For instructions that take at least one operand, the first operand is often a destination for data to be written and is usually a source as well. The INC EAX instruction will read the value of EAX, add one, and write the value back to EAX. Any operands after the first are generally only read and not written. One notable exception to that rule is the XCHG instruction which can swap two registers or a register and a memory location.
Instructions can also have “prefixes” which modify the behavior of the instruction. The two types you are most likely to encounter are LOCK for making certain read/modify/write operations atomic, and REP/REPZ/REPNZ which are used for “string” operations for copying/comparing a sequence of bytes.
Memory operands
Intel has a flexible (and complex) set of memory addressing modes. Luckily, when reading the code you don’t need to know most of this because with Intel syntax the address expression will always be described as a simple expression such as:
mov rbp,[rsp-170h]
The most complex expressions can contain two registers, a constant, and a “scale factor” for one of the registers. For instance:
mov rax,dword ptr [rbp+rcx*4+1234h]
One special instruction that takes a memory address is the LEA instruction, which stands for Load Effective Address. Unlike every other instruction that takes a memory operand, this one does not read or write to the address, but only calculates the effective address where the memory load or store would be. There’s really no reason why the address actually has to be a memory location at all, so you sometimes see LEA being used to combine a few arithmetic operations together, since it’s sometimes smaller and faster to do a single LEA instruction than several ADD instructions.
Registers
The x64 register set has an instruction pointer (RIP) and 16 general purpose registers (RAX, RCX, RDX, RBX, RSP, RBP, RSI, RDI, R8-R15)3. By “General Purpose” we mean that they can be generally used for storing whatever you want in them. For instance, a MOV instruction can be used to move values into/out of any of the general purpose registers, but cannot directly access the instruction pointer, RIP. Although they can be used for general purpose, some of the registers have special purposes and are used implicitly by certain instructions. For example, the RSP register is always used with any operation that touches the stack, like the CALL and PUSH instructions. The RSI and RDI registers are used implicitly for any of the “string operations” like MOVS. Some registers are simply more efficient to use in certain cases, but when reading assembly code you generally don’t need to worry about this.
While all of these registers are 64 bits, x86 can use smaller parts of most registers, and we use a different name when talking about the smaller parts of the registers. EAX is the low 32 bits of RAX. AX is the low 16 bits of RAX. AL is the low 8 bits of RAX. And we also have AH that can be used to describe the high 8 bits of AX. In general, you can use these to manipulate the bits of a larger register, such as using MOV AX, 0 to clear out the low 16 bits of RAX. The one strange exception is that writing to the low 32-bits of a 64-bit register will clear the high 32-bits to 0.
0:000> rrax=1234567812345678
0:000> u . L2
00007ffb`a8980959 b834120000 mov eax,1234h
00007ffb`a898095f cc int 3
0:000> rrax
rax=1234567812345678
0:000> p
00007ffb`a898095e cc int 3
0:000> rrax
rax=0000000000001234
Note that there are a bunch of other registers, including segment registers, debug registers, and control registers. If you’re just starting out with reading disassembly, you won’t need to worry about these yet. Segment registers can affect how memory loads and stores are handled. Debug registers are used to cause an exception for certain memory addresses (like a break on a memory read at a certain address). Control registers are used from kernel mode to control system-level configuration.
Common instructions
The most common instruction by an order of magnitude is the MOV instruction. This can be used to read memory, write memory, and to copy data between registers. Because Intel syntax puts the destination as the left-hand operand, you can think of a MOV A, B instruction as if it is just an assignment statement A = B.
The CALL instruction is for calling a function. This can be a direct address, or it can be an indirect address where the location of the target function is stored in a register or memory, which is useful for cases such as function tables. The actual behavior of the CALL instruction is to take the current instruction pointer, push it to the stack, and then replace the current instruction pointer with the value of the first operand.4. The RET (return) instruction does the exact opposite, and pops a value off the stack into the current instruction pointer. The JMP instruction is the same as CALL except that it does not push a return address on the stack. It’s usually used for control flow within a function.
There are also a set of logical and arithmetic operations that follow a standard pattern. This includes ADD dest, src, SUB dest, src, AND dest, src and XOR dest, src. There are a bunch of these and they all work almost identically. ADD RAX, RBX in pseudocode would be RAX = RAX + RBX. In addition to setting the destination to the result of the operation, they also set a number of “flags” based on the operation. For instance, the “zero flag” is set if the result was zero. The flags are important because they control all of the conditional operations. For example, the JZ (Jump if Zero) is a jump that’s conditional on the zero flag. If the zero flag is set, the CPU will start executing instructions at the address specified as an operand. If not, it will continue executing the instructions following the JZ. The same instruction has another name, which is JE (Jump if Equal). This tells you a little about why this flag is useful. If you want to check if two values are equal, you can subtract them and see if the result is zero. And in fact, that’s exactly what the CMP first, second instruction is. It’s a SUB instruction but without storing the data back to the first operand. The point is that it will set all of the flags as if it did a subtraction, but not store the result. Using the other flags, we can do other conditional jumps, such as JNE (Jump if Not Equal), JB (Jump if Below), JLE (Jump if Less or Equal). Note that there are some very similarly-named instructions like JB (Jump if Below) and JL (Jump if Less), and the difference is that JB is used for unsigned comparisons, and JL is used for signed comparisons. There are lots of different conditional jumps, but the most frequently seen are JE (also known as JZ) and JNZ (also known as JNE). You will see some combination of JB, JS, JL and others depending on whether the program uses more signed or unsigned numbers.
Similar to the CMP instruction is the TEST instruction, which also sets flags without writing to a destination register, but this one does an AND operation instead of a subtraction. A common use for this instruction, as the name implies, is testing if a bit is set.
There are a few instructions that take a single operand. DEC and INC will decrement or increment a register (or memory location), while NEG will negate a number (two’s complement), and NOT will invert every bit of a register or memory location.
The NOP instruction does… nothing. It’s short for No OPeration. While compilers have a few uses for this instruction, one that comes in handy is when you want to disable a small chunk of code (which we sometimes call “NOP-ing out” the instructions).
The last common instruction I’ll mention is the INT instruction. It always takes a constant operand of a single byte value. It’s short for “INTerrupt” and is used to trigger a “software interrupt”, which will switch the CPU into kernel mode and start running the code that corresponds to the interrupt number (the interrupt handler). Two important uses are breakpoints (which are always INT 3) and system/kernel calls, although the latter use has been mostly replaced with the SYSCALL/SYSENTER instructions because they are better suited for that purpose.
See, it’s not so hard!
If you’ve made it this far, you should have the basic information you need to start understanding assembly code. The best way to improve past this point is to actually start reading the code that a compiler generates. The best way to do that for sample programs is to use Compiler Explorer, which will neatly color code the correlation between source code and assembly. I also think it’s very useful to step through assembly code and see how the registers change. For that, WinDbg is my preferred tool, but any debugger that can step at the assembly level (and not source line!) will give you a similar experience. Lastly, when you want to really understand every last detail of how an instruction works, make sure you download the latest copy of the Intel Software Developer Manuals, which we usually just call “The SDM”. It’s incredibly dense, but has every detail of every instruction, as well as everything else you can imagine about low level x86 and x64 programming.
Was this useful? Have any questions that weren’t answered here? Did I make any mistakes? Let me know on Twitter or Mastodon!
Footnotes
- I’m not going to split hairs about assembly language vs. machine code. If you care about the distinction, this blog post is probably not very relevant to you. Same goes if you want to talk about microcode instead of machine code.
- In fact, there are no x86 instructions that have two explicit memory operands! There are instructions that can read from one memory address and write to another, but one of those addresses will be implicit via some other register. For instance, the
PUSH [addr]instruction can read a value from one address, and then write it at the current stack pointer. - Those of you with sharp eyes will notice I listed RAX, RCX, RDX, RBX and not RAX, RBX, RCX, RDX. That’s because RAX, RCX, RDX, RBX is the correct order for the registers and almost everyone gets this wrong in diagrams online. It’s really not important 99% of the time, but if you look any place where the registers are indexed or stored into memory, it’s always this order.
- To be more precise, the operand is evaluated and stored as a temporary value, and then the instruction pointer is pushed to the stack. This is important if the operand references RSP! The first time I wrote CPU emulation for this when working on Time Travel Debugging, I got this wrong. It seemed to work just fine but randomly crashed when some programs jumped to the wrong address!