Snippy: An AI Assistant With Eyes
While I no longer work on WinDbg, I still spend a lot of time thinking about how to make tools so people can build things faster. With WinDbg, I tried to do that by putting more debugging power at people’s fingertips in a way that was easier to use. Recently, everyone is looking for ways to use LLMs to build things faster. But for most people using something like ChatGPT means pasting text back and forth between your different tools. We’ve seen some better integrations with tooling like in VS Code, but I think there are still a ton of tools where an LLM can be useful but there’s just no “glue” connecting it to your apps.
At Augmend, we think that giving an AI assistant “eyes” into what you’re doing can solve some of these problems. When we saw the demo that Suneel Matham had for sharing your screen with GPT-4, we knew we wanted to implement our own version, and it was a great chance to use our cross-platform screen capture Rust crate, CrabGrab. We built a new screen-sharing GPT assistant with CrabGrab, and we called it Snippy! We’ve made both CrabGrab and Snippy open source under MIT or Apache-2.0, so I’d love to see folks try these and make their own versions.
Demo
First, a quick demo of what Snippy can do, and then I’ll talk about how we built it. If you want to follow along, just clone the repo and run cargo run on Windows or macOS. When you first run Snippy, you’ll see a prompt for your OpenAI API key.
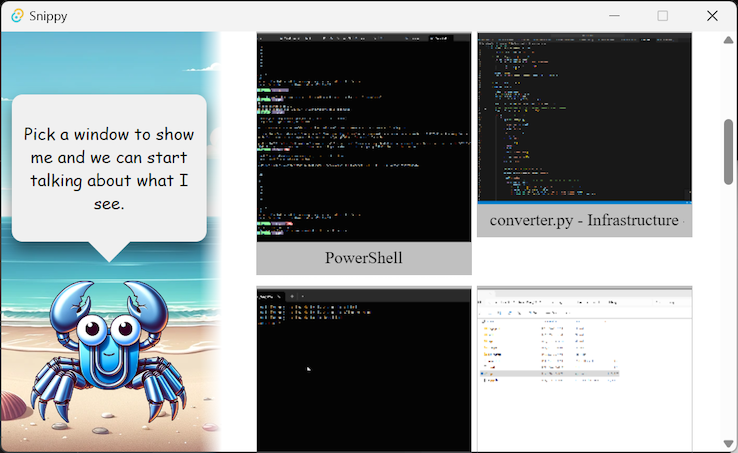
After that, you can pick a window to “chat” with.
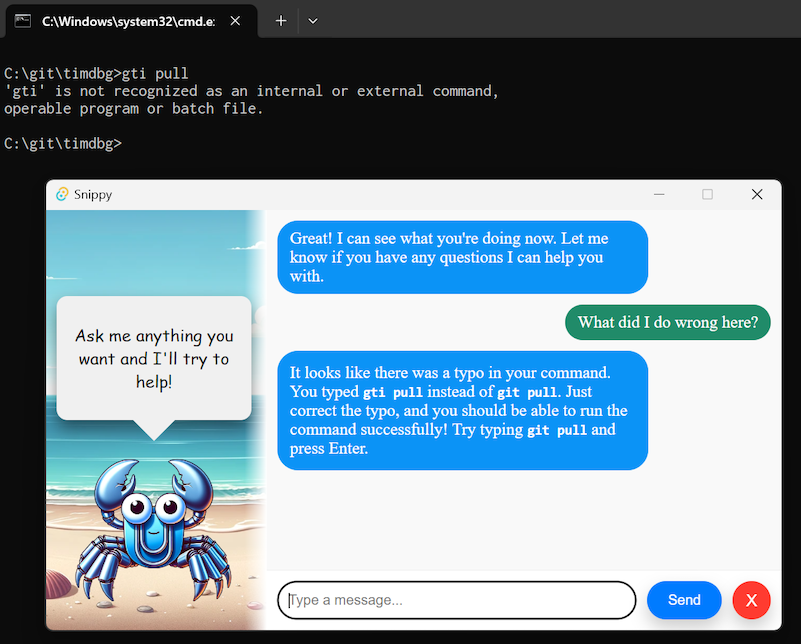
From there, you can start a “chat” where each message will include a screenshot of your app. This uses GPT-4 with vision, which is powerful enough to understand the text on the screen as well as the application you’re using. (Under the hood you could swap this out with LLaVA or other multimodal LLMs)
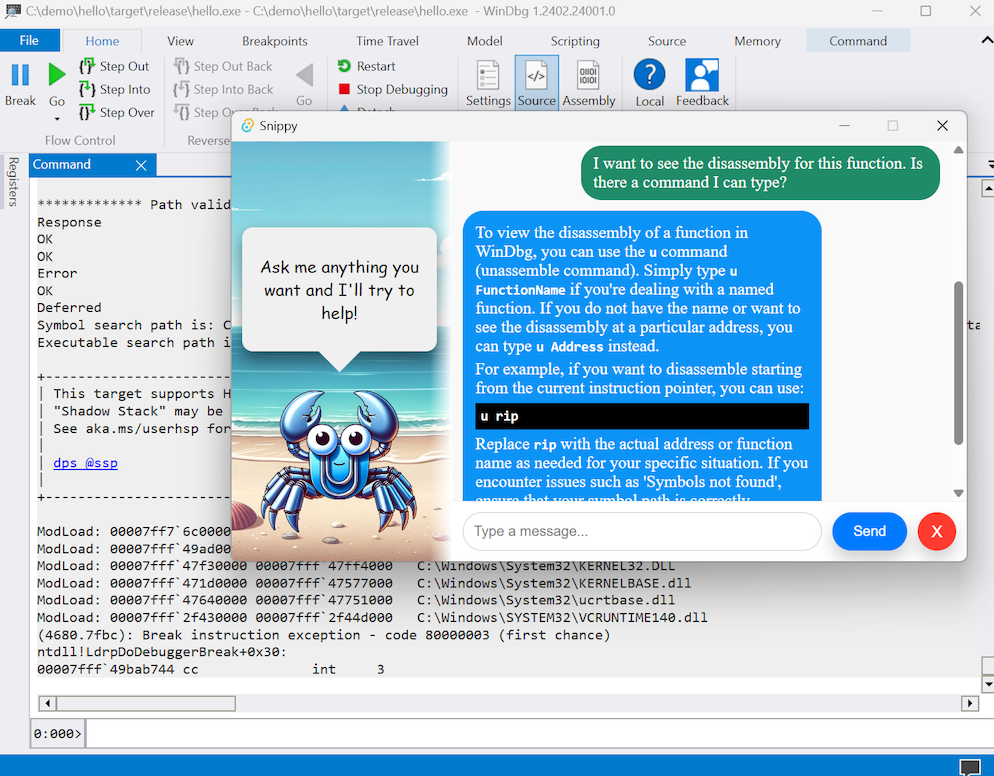
Besides just reading text, an LLM can also use context cues from what you’re looking at to give correct answers for questions that would otherwise be ambiguous. Here I just asked how to get the disassembly of a function but didn’t tell GPT what debugger I was using. It “sees” that I’m using WinDbg and gives the correct disassembly command! Without that context, ChatGPT usually tells me to use objdump or gdb.
How it works
The code for Snippy is fairly simple, and uses three main pieces of tech. First, for the UI we’re using Tauri. I’m a big fan of Tauri, because it’s easy to use, low overhead, and cross-platform. It also makes it very easy for JavaScript UI code to talk to Rust code, which is great because that lets us use our cross-platform screen capture crate called CrabGrab for grabbing screenshots of applications. Finally, we make a base64 encoded PNG along with our system prompt and send it to GPT-4.
Tauri
Our rust entrypoint just sets up our Tauri window with the set of Rust functions that we want to be callable from JS as part of the setup.
fn main() {
tauri::Builder::default()
.invoke_handler(tauri::generate_handler![
get_windows,
begin_capture,
end_capture,
send_message,
has_api_key,
set_api_key,
])
.setup(|app| {
let main_window = app.get_window("main").expect("Expected app to have main window");
//main_window.open_devtools();
Ok(())
})
.run(tauri::generate_context!())
.expect("error while running tauri application");
}
From there the JS side of the code will drive most of the experience. When the document is loaded, we kick off the process by checking if an API key is available and showing that prompt, and calling the rust get_windows code to enumerate thumbnails.
document.addEventListener("DOMContentLoaded", async (e) => {
// Skipping lots of vanilla JS DOM stuff here...
let has_key = await window.__TAURI__.invoke("has_api_key");
if (!has_key) {
document.getElementById("config-panel-outer").hidden = false;
document.getElementById("tile-container-outer").hidden = true;
document.getElementById("snippy-text").innerText = "Before we can chat, we need to set up a few things.";
}
let windows_json_string = await window.__TAURI__.invoke("get_windows", {req: 1});
});
CrabGrab
Back in the rust implementation of get_windows, we see it call into CrabGrab to enumerate windows. We’ll generate an ID for each window so we can get back to the CapturableWindow that CrabGrab gives us.
#[tauri::command]
async fn get_windows(app: AppHandle, req: i32) -> String {
// We set up some filters for the windows to grab only things that look like applications
let filter = CapturableContentFilter {
windows: Some(CapturableWindowFilter {
desktop_windows: false,
onscreen_only: true
}),
displays: false,
};
// We create a CrabGrab CapturableContent and use our filter to get the list of windows we want to show the user
let content = CapturableContent::new(filter).await.unwrap();
let window_list: Vec<_> = {
let mut window_map = WINDOW_MAP.lock();
for window in content.windows() {
if !window_map.contains_key(&window) {
let id = WINDOW_ID_COUNTER.fetch_add(1, atomic::Ordering::SeqCst);
window_map.insert(window, id);
}
};
window_map.iter().map(|(window, id)| (window.clone(), *id)).collect()
};
For each window, we scale it down and make it a base64-encoded PNG (There are better ways of sending images to the JS side, but this way is fairly concise and the same as how we’ll send the images to the language model). The information for each window found is sent back via a Tauri event called “window_found” along with the title and an ID.
for (window, id) in window_list.iter() {
let screenshot_config = CaptureConfig::with_window(window.clone(), CapturePixelFormat::Bgra8888).unwrap();
let screenshot_task = take_screenshot(screenshot_config);
let screenshot_result = timeout(Duration::from_millis(250), screenshot_task).await;
let screenshot = match screenshot_result {
Ok(output) => output,
_ => continue
};
if let Ok(Ok(FrameBitmap::BgraUnorm8x4(image_bitmap_bgra8888))) = screenshot.map(|frame| frame.get_bitmap()) {
let image_base64 = make_scaled_base64_png_from_bitmap(image_bitmap_bgra8888, 300, 200);
let item = Item {
id: *id,
thumbnail: image_base64,
title: window.title(),
req
};
let item_json = serde_json::to_string(&item).unwrap();
app.emit_all("window_found", item).unwrap();
}
}
}
The JS side subscribes to this event and creates an HTML element for each window that was found. When a user clicks on a specific window, we start capturing the window using the CrabGrab CaptureStream, which just takes a callback function that is called for each video frame captured. For our purposes here, we’ll just use this for grabbing individual frames as needed, but you could also take these frames and run it through a video encoder, like we do in the full Augmend client.
#[tauri::command]
fn begin_capture(app_handle: tauri::AppHandle, window_id: u64) -> Result<(), String> {
// First we need to map the generated window ID back to the CapturableWindow from CrabGrab
let mut active_stream = ACTIVE_STREAM.lock();
let window_map = WINDOW_MAP.lock();
for (window, id) in window_map.iter() {
if *id == window_id {
let config = CaptureConfig::with_window(window.clone(), CapturePixelFormat::Bgra8888)
.map_err(|error| error.to_string())?;
let stream = CaptureStream::new(config, |event_result| {
// This gets called for each frame captured from the window.
match event_result {
Ok(StreamEvent::Video(frame)) => {
let mut frame_req = FRAME_REQUEST.lock();
if let Some(req) = frame_req.take() {
req.send(frame).unwrap();
}
},
_ => {}
}
GPT
When a user sends a message, Snippy grabs a frame from the current application and encodes it as a base64 PNG. Then it includes that PNG along with a system prompt and sends it off to the OpenAI endpoint. The result gets passed back to the JavaScript side where some HTML elements are created for the chat message.
pub async fn send_request(msg: String, base64_png: String) -> Result<String, String> {
let prompt = "You are a helpful assistant named 'Snippy' in the style of 'Clippy' from Microsoft Office. \
You can see the current window that the user is looking at. You can answer questions the user has about the current window. \
If the user seems to have no specific question, feel free to offer advice on what they are currently looking at, but try to be concise. \
";
let body = json!({
"model": "gpt-4-turbo",
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": prompt
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": msg
},
{
"type": "image_url",
"image_url": {
"url": format!("data:image/png;base64,{}", base64_png)
}
}
]
}
],
"max_tokens": 300
});
There’s a lot more we could do here, like including the full chat history, but to keep things simple (and less expensive) we’re just sending the current message along with an image of the currently shared application. But even in this simple form, it’s surprisingly powerful!
Make your own!
The hardest part of this whole project was the screen capture. There seemed to be no good cross-platform libraries for screen capture, and this was a big hurdle for both this project and the products we want to build at Augmend. To solve this problem we created CrabGrab as an open source project. We’re hoping this will make it much easier for other people to create similar projects. You can see a few other examples of CrabGrab in the repo. Try it out and let us know what you build!